
麻雀AI「Lucky J」についてのテンセント公式記事の日本語訳
天鳳10段にわずか1321戦で到達し、更にはその牌譜で話題をさらった麻雀AI「Lucky J 」。
そのLuckyJについて開発元であるテンセント AI Labが記事を出していたため、こちらを日本語訳させて頂きました。
翻訳と掲載についてはテンセント担当者に許諾を頂いています。連絡をしてくださったゆうせーさん(@getawonarashite)、ありがとうございます。
なお、AI技術に詳しくない方向けにはLucky JをNAGA / Suphxと技術的に比較しつつ打牌傾向の違いを解説した記事があるので、こちらを読んで頂けると幸いです。
最強AI【LuckyJ】とNAGA/Suphx徹底比較!技術の違いから見える打牌の違い
2023年5月30日、ネット麻雀界隈に激震が走りました。 LuckyJという麻雀AIが一ヶ月ほどで特上卓で10段を達成しました。 しかも特上卓東南戦で1000戦以上打って安定段位が約…

テンセントAIが国際麻雀プラットフォームでトップ、世界最高得点を更新
テンセント 2023-07-11 14:00 カテゴリー: 広東省
今日、テンセントのAI、「超絶技巧LuckyJ」が麻雀デビューを果たした:
テンセントの麻雀AIは日本の麻雀プラットフォーム、天鳳特上卓で安定段位10.68に達した。
AIが麻雀分野で達成した最高の成績を更新し、テンセント研究開発チームの意思決定AIの方向性を象徴し、業界をリードする成果とブレークスルーを達成した。
あなたはきっと疑問に思ったでしょう:
なぜ中国の麻雀AIは日本のプラットフォームに行くのか?
なぜ麻雀に参入するのに何年もかかったのか?
説明しましょう。
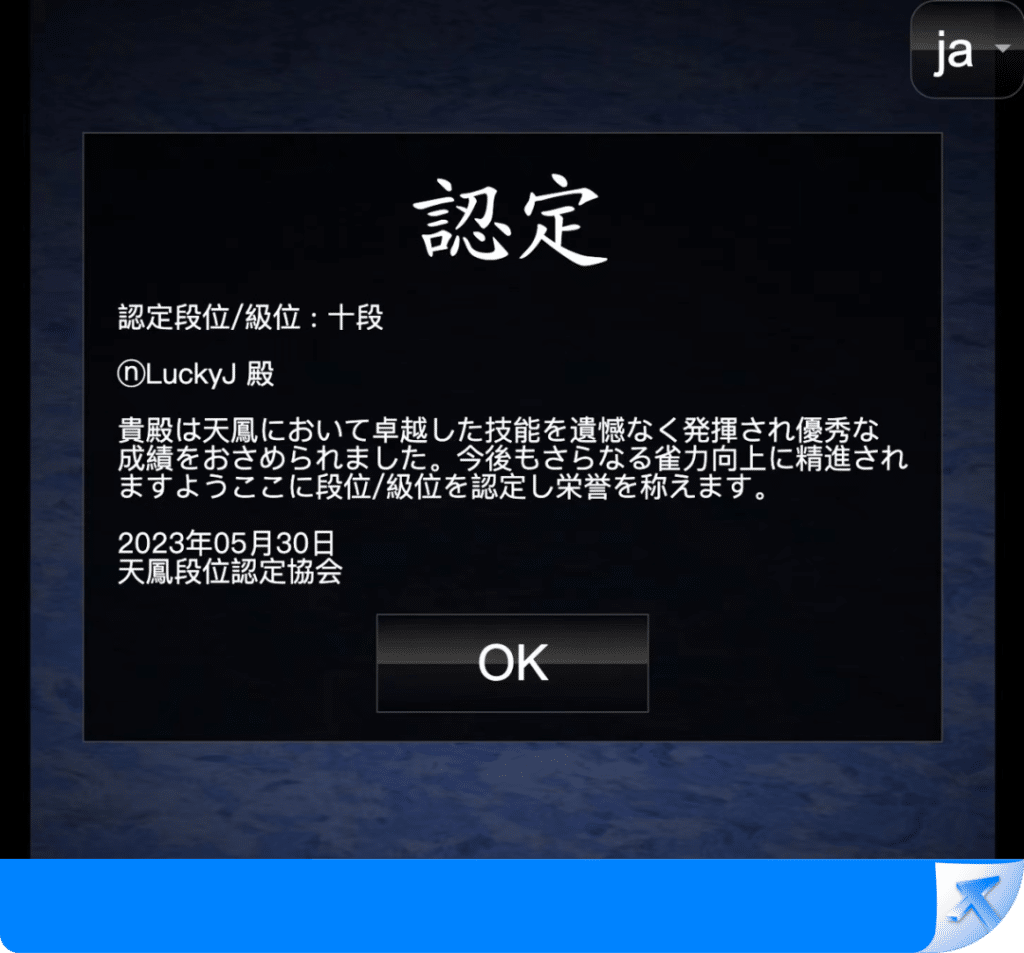
天鳳安定段位10段
まず最初の質問です:なぜ中国の麻雀AIは日本のプラットフォームに行くのか?
まず、天鳳というプラットフォームを紹介します。
「天鳳は日本の有名な麻雀のプラットフォームで、体系的な競技ルールと専門的な段位ルールを持っており、プロ麻雀界に広く認知されています。
世界中の麻雀AIが基本的にここで訓練し、段位戦をプレイしています。
(麻雀AIの世界で有名になるには、最も多くのAIがいるプラットフォームで結果を出し、存在感を示さなければなりません)
天鳳の"段位戦"は、私たちが王者栄耀(訳注:テンセントゲームズが配信しているMOBAゲーム)をプレイするのと少し似ています。プレイしたゲーム数と蓄積されたポイントに応じて、あなたの段位(訳注:Apexやバロラント、LoLでいうランク)を決定しています。:ブロンズ......ダイヤモンド、スターフレア、王、栄光の王。
天鳳は、1〜11段までのランクが存在し、10段は王者栄耀の栄光の王のセクションに相当します。
天鳳では、7段以上のプレイヤーが3,037人おり、全体の約1%に相当します。10段に達したプレイヤーは27人(AIを含む)だけで、0.01%未満です。
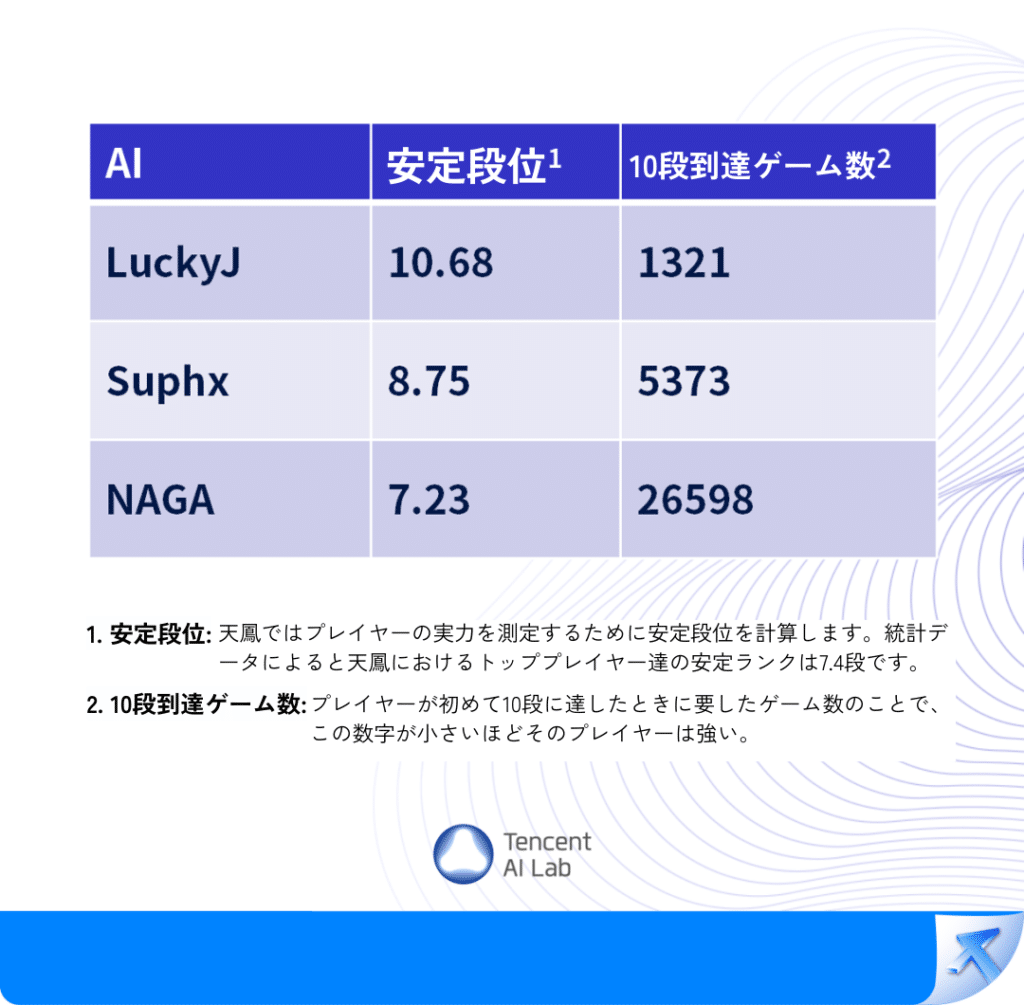
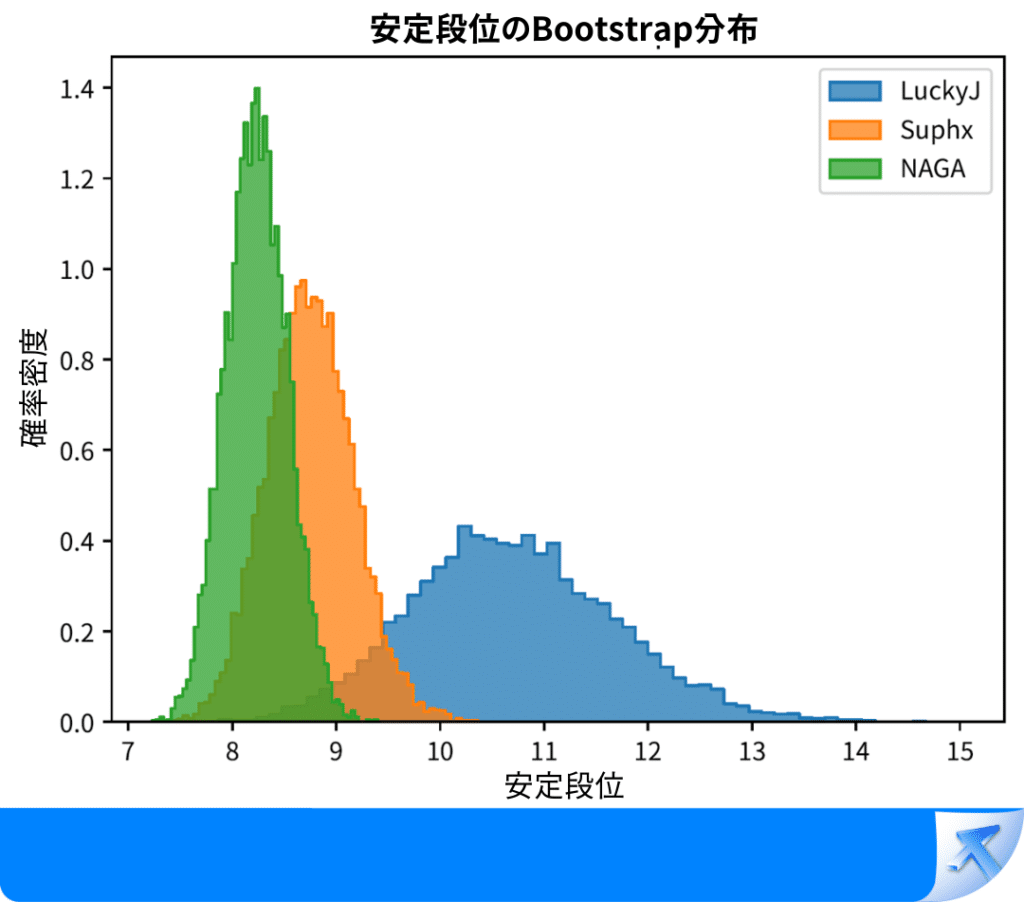
天鳳安定段位ブートストラップ法における分布。
LuckyJはこれまで最強だった2つの日本麻雀AI(Suphx、NAGA)より有意に強い。
LuckyJ vs Suphx p値=0.02883
LuckyJ vs NAGA p値=0.00003
この3種のAIは現在、麻雀AIランキングのトップ3であり、Jedi LuckyJは10段に到達するまでに1000試合以上を要し、特上卓で1000試合以上を行った全プレイヤーの中で、安定段位で1位となっている。
天鳳十段、日本麻雀戦術研究家、ゆうせー(日本出身)、天鳳ID:黒猫@ぺろぺろ☆ のコメント:
LuckyJは "完璧 "に見えます!
ある時は、安全牌を持つなどの戦略によって放銃率を下げています。
またある時は、手牌進行に分岐が複数あっても、LuckyJはこれらの複雑な分岐をスムーズに進めることができます。
麻雀は中国発祥の国民的娯楽だ。
たまたま近所を通りかかったおじいちゃん、おばあちゃんが隠れた名人かもしれない。

特筆すべきは、LuckyJが日本麻雀の天鳳十段に達しただけでなく、全国標準麻雀のオフライン招待大会で6人のプロ雀士を破ったことだ。(中国では麻雀は古くからプロスポーツであり、プロトーナメントに参加する選手も多い)
全国標準麻雀のトッププロを破った初の麻雀AIとなった。
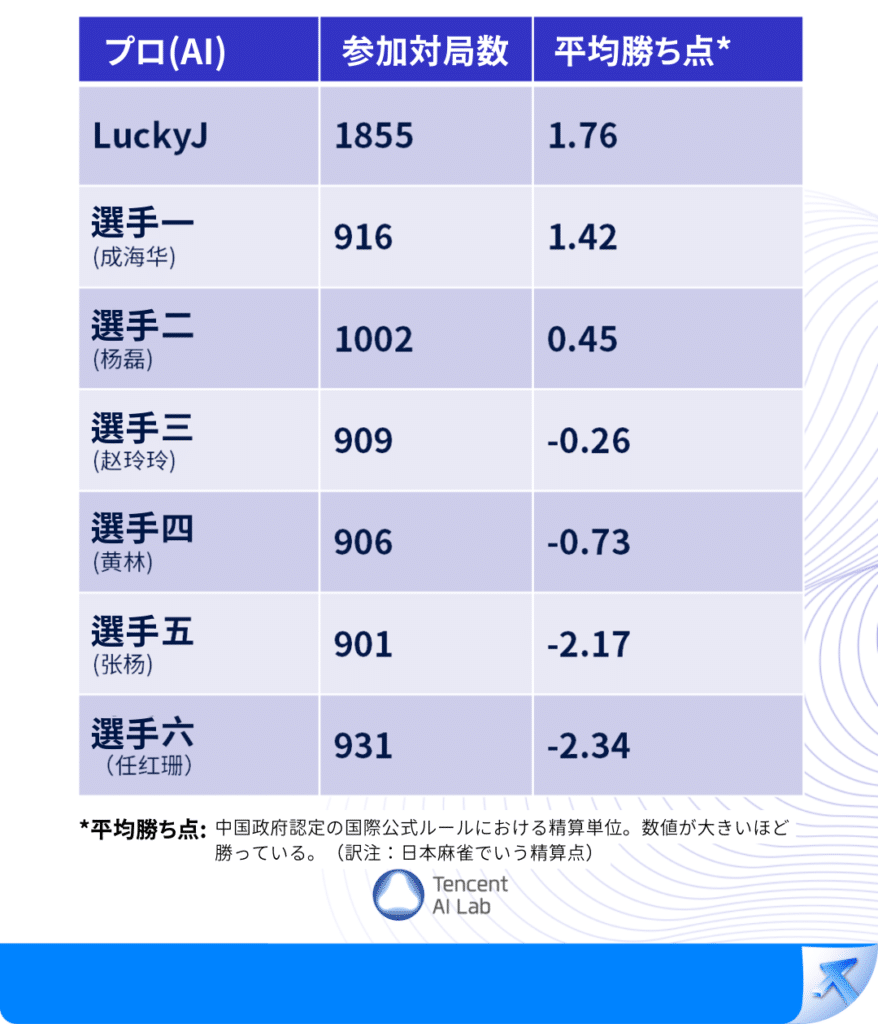
楊蕾、プロ国家標準麻雀選手、麻雀スポーツ協会会長、最高成績:2007年中国牌王トーナメント牌王、2007年キングオブキングストーナメント覇者:
数ヶ月にわたるテンセント麻将AIとの対戦テストの結果、AIの攻守に非常に感心させられました。
攻撃では、AIは素早く戦略を形成し、変化に対応し、状況に応じて最適な選択を行うことができます。防御では、初期段階でテンポと方向をコントロールし、後期には精密な調整や果断な手の切り方ができ、逆境でも大きな成功を収めることができます。
私たちがよく「妙手」とか「ひらめき」と呼ぶような経験や直感に基づいた危険な選択も、AIにとってはおそらく日常的な操作と見なされるでしょう。
完全情報ゲームと不完全情報ゲーム
第二の質問:なぜ麻雀に参入するのに何年もかかったのか?
それは、麻雀がAIにとって困難な問題だからです。
囲碁やチェスなどと比較して、両プレーヤーの駒がすべて盤上にあり、ゲームの状態全体が見える(完全情報ゲーム)という点に対し、麻雀やテキサスホールデムポーカーなどはプレーヤーの手札が見えないという共通点があります(不完全情報ゲーム)。
完全情報ゲームであろうと不完全情報ゲームであろうと、過去のボードゲームのAIシステムには次の2つの主要な技術要素があります:
オフライントレーニング:
オフライントレーニングの目的は、強化学習や他のアルゴリズムを使用してAIにゲームのプレイ方法を学ばせ、固定のオフライン戦略(オフラインポリシー:AIがさまざまなゲーム状態で自分の動きに生成する戦略)を得ることです。
オンラインサーチ:
オンラインプレイ中、オンラインサーチ技術は強力な計算能力を使用してさまざまな可能性を徹底的に探索し、オフラインポリシーに基づいてリアルタイムで戦略を調整し、勝利への道を見つけることができます。
つまり、あなたが囲碁をプレイしている間に1手進めるかもしれませんが、AIはすでに頭の中で数千の可能な手をシミュレーションして最善の手を選んでいます。
私たちが知っているように、囲碁AIのAlphaGoは強化学習とモンテカルロ木探索の組み合わせを活用しています。

しかしながら、完全情報ゲームの技術は非完全情報のゲームには適用できません。
具体的には、従来の強化学習は非完全情報のゲームの最適戦略に収束できません。
さらに、モンテカルロ木探索は対戦相手の手牌の可視性を必要とします。
したがって、テキサスホールデムAIでは、「後悔値最小化アルゴリズム」(訳注:Counterfactual Regret Minimization、ナッシュ均衡を近似的に求めるアルゴリズム)と「安全サブゲーム探索」(訳注:Safe Subgame Search)を採用しています。
テキサスホールデムポーカーでは、隠された2枚のカードのみが関係しており、計算の複雑さは特に高くありません。従って、従来のアルゴリズムを適用するためにコンピュータの計算能力を活用できます。
一方、麻雀は136枚の牌が存在し、各プレーヤーの手牌は13枚の牌から成り立っているため、膨大な量の隠された情報があります。これはテキサスホールデムポーカーの何十億倍にも相当します。
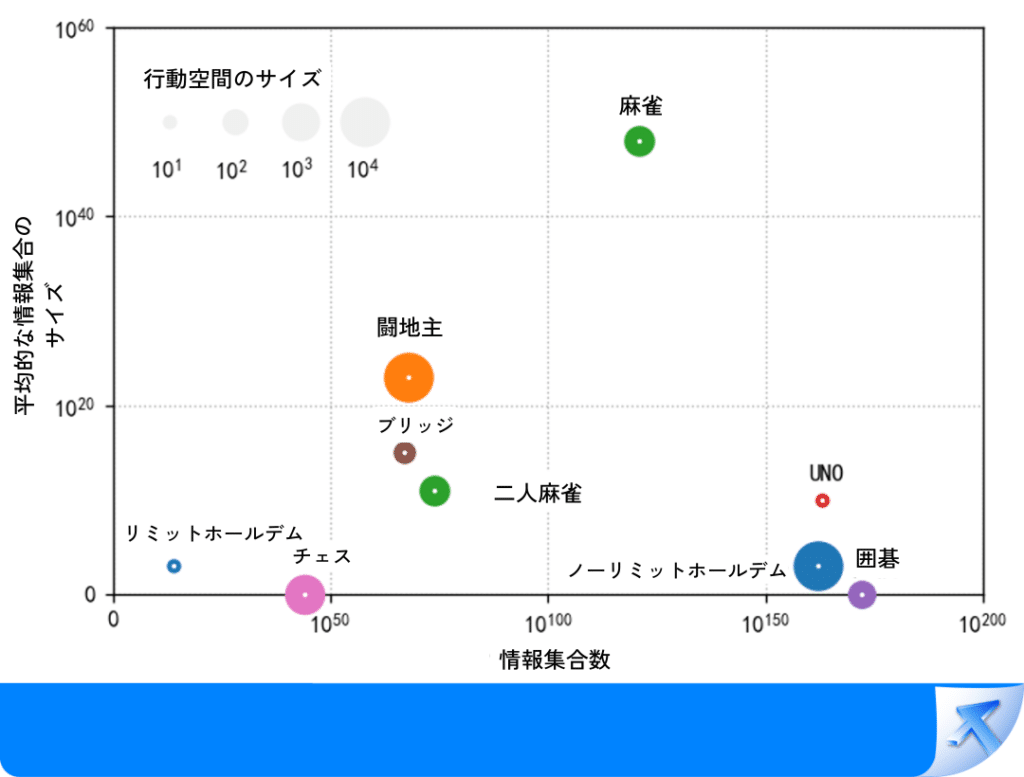
上に示したように、横軸の情報集合の数は、観測可能な状態、すなわちカードに関する情報の量を示し、縦軸の情報集合の平均サイズは、隠された情報、すなわち他のすべての対戦相手の手の可能性の量を示す。
また、麻雀では、通常の牌の取り換えや捨てる行為に加えて、プレーヤーは「チー」(吃牌)、"ポン"(碰牌)、"カン"(杠牌)をするかどうか、また和了牌(ツモった牌を使って和了ること)を宣言するかどうかを決定しなければなりません。
誰か一人のプレーヤーの行動が、牌を取る順序を変える可能性があり、非常に多くの判断が必要になります。

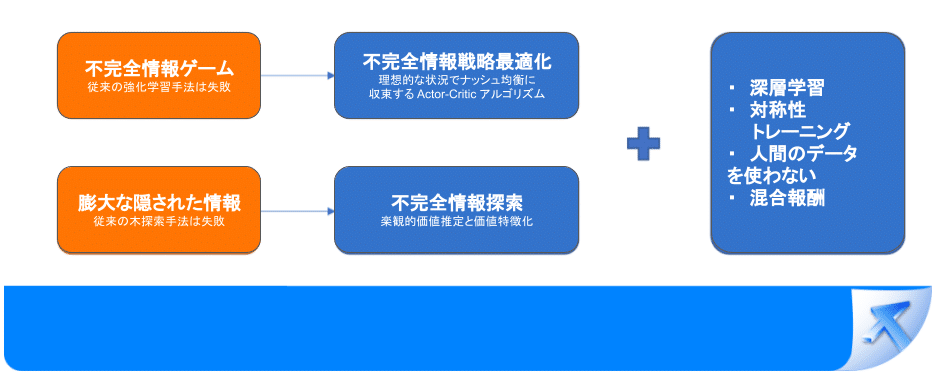
要するに、麻雀というゲームにおいては、従来の方法は全く通用しません:
従来のオフライン戦略トレーニング方法は、速く計算できるが良い結果が得られない(強化学習)、あるいは良い結果が得られるが計算が遅い(後悔値最小化アルゴリズム)。
従来のオンライン探索アルゴリズムは、適用できない(モンテカルロ木探索)か、計算複雑度が高すぎる(安全サブゲーム探索)。
したがって、麻雀AIが強力な麻雀を打ちたい場合は、新しい方法を見つける必要があります:
強力なオフライン戦略をトレーニングできるだけでなく、効率的なオンライン探索にも対応している方法を見つける必要があります。
意思決定AIの能力の限界を超えるアルゴリズム革新
そこで、テンセントAI Labの研究者は新しい戦略最適化アルゴリズムであるACH(actor critic hedge)を提案しました。
ACHは、強化学習と後悔値最小化に基づく自己対戦技術を採用し、AIがゼロから自己学習し向上し、最終的に最強の混合戦略に収束できるようにしました。
このアルゴリズムは、伝統的な強化学習の拡張性が高い(速く計算できる)利点を持ちつつ、一部の後悔値最小化アルゴリズムの理論的特性(良い計算結果)も受け継いでいます。従来の強化学習方法と比較して、この戦略最適化アルゴリズムは不完全情報ゲームでよりバランスの取れた戦略(攻守兼備)を学習し、より堅牢性を持っています。
同時に、楽観的価値推定の考えに基づいて、効率的な不完全情報探索手法を提案しています。
まず、探索木に対して効果的な変換と剪定を行い、AIが無駄な探索を大幅に避け、探索効率を大幅に向上させています。
その他に、過去の探索とオフライン戦略の組み合わせとは異なり、探索結果を一種の"特徴"として自社開発の戦略ニューラルネットワークに入力することで、大量の隠れた情報を持つゲーム状態でも、AIが現在の戦略をリアルタイムで調整できるようにしています。
これにより、大規模ゲームへの適用が難しい不完全情報探索の複雑性の問題を解決し、深層強化学習と不完全情報探索を組み合わせることを可能にした。
実際、私たちが麻雀AIを研究しているのは、ゲームや競技のためだけではありません。
麻雀は私たちの生活環境にとても似ているからです。
どちらも隠された情報や不確定要素が多く、複雑な推論戦略やランダム性を伴うゲームの中で意思決定をする必要がある。
麻雀AIのトレーニングは、実は人間の世界をよりよく理解するためのAIのトレーニングとなります。
最終的には、できるだけ早い段階で金融取引、自動運転、輸送物流、オークションシステムなど、AIが人間の生活に入り込むことを可能にする......
現実世界の複雑な問題を解決するために。

